


Building a Toy Database: Concurrency is Hard
Hey folks, it's been a while. Here's some news on Bazoola, my precious toy database, which already reached version 0.0.7!
Demo App
Meet the "Task manager" - a flask-based app demonstrating current capabilities of Bazoola:
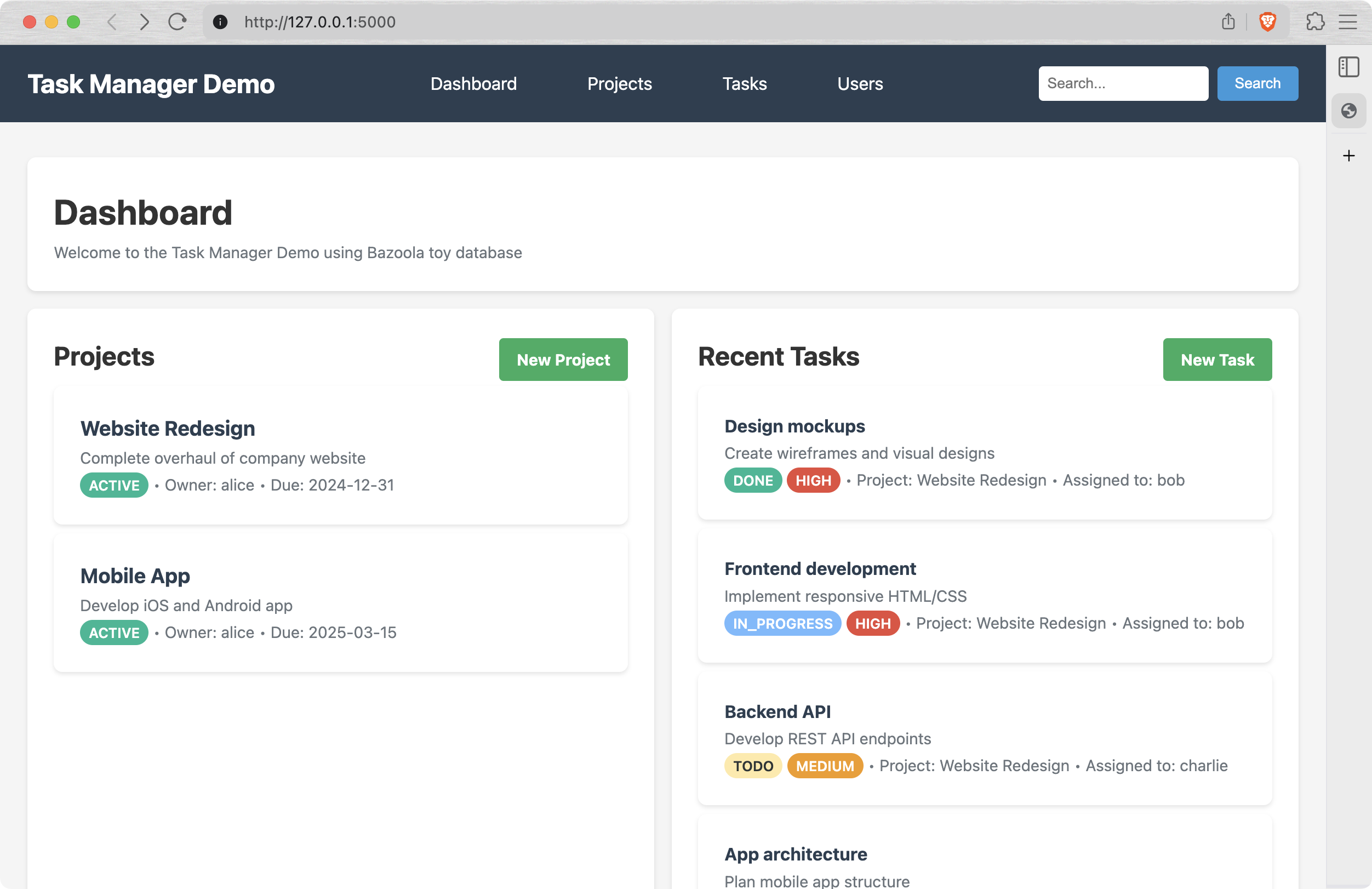
In order to run the task manager:
git clone https://github.com/ddoroshev/bazoola.git
cd bazoola
pip install bazoola
python demo/app.py
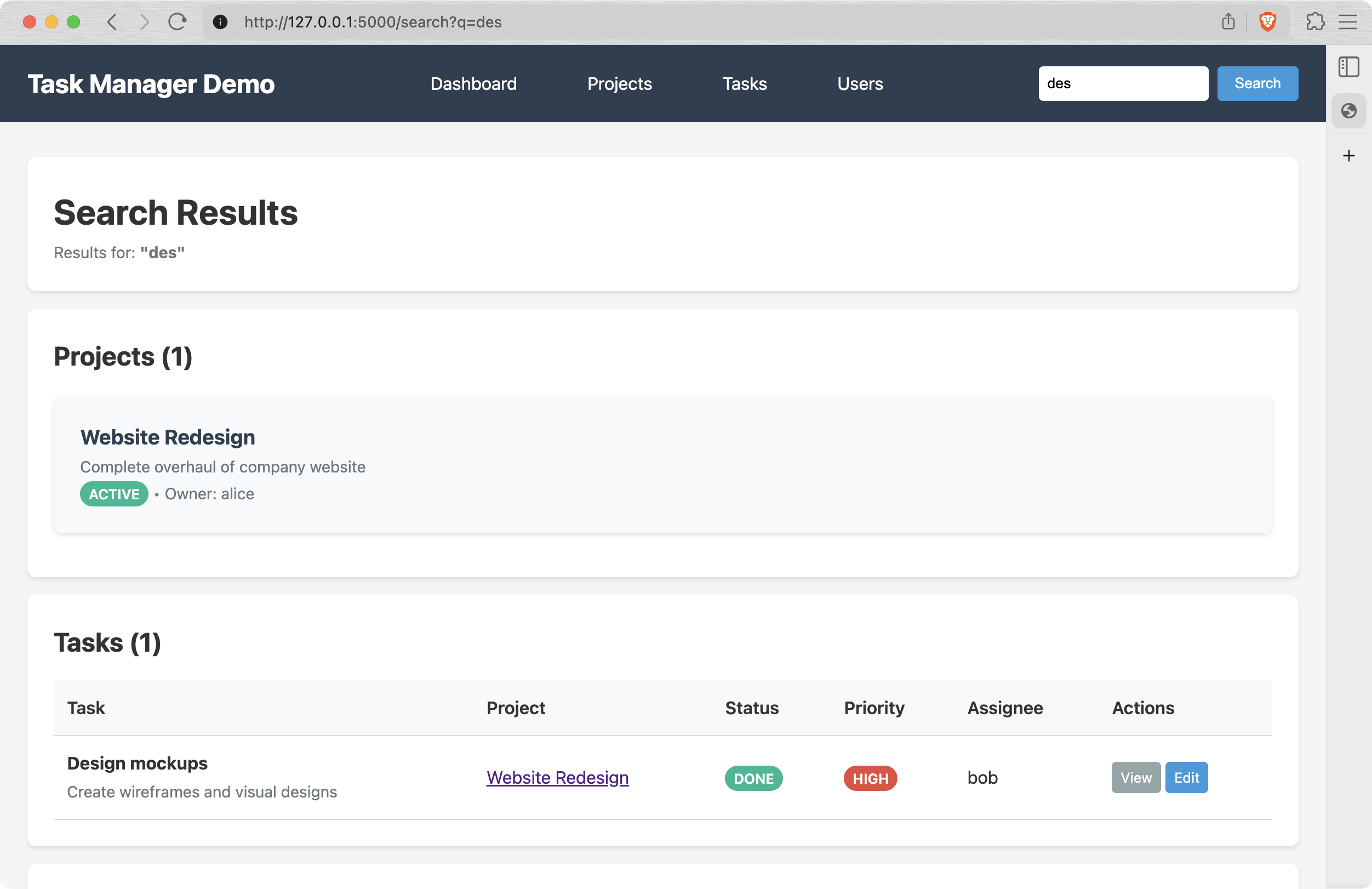
Then open http://127.0.0.1:5000 in your browser, and Bob's your uncle. The schemas and tables are all pre-created and filled with demo data, so you can browse and edit it, checking the explanation at the bottom of the page. For example, you can try to search design-related projects and tasks by "des" query:
If you scroll down a bit, there's an explanation of how it actually works:
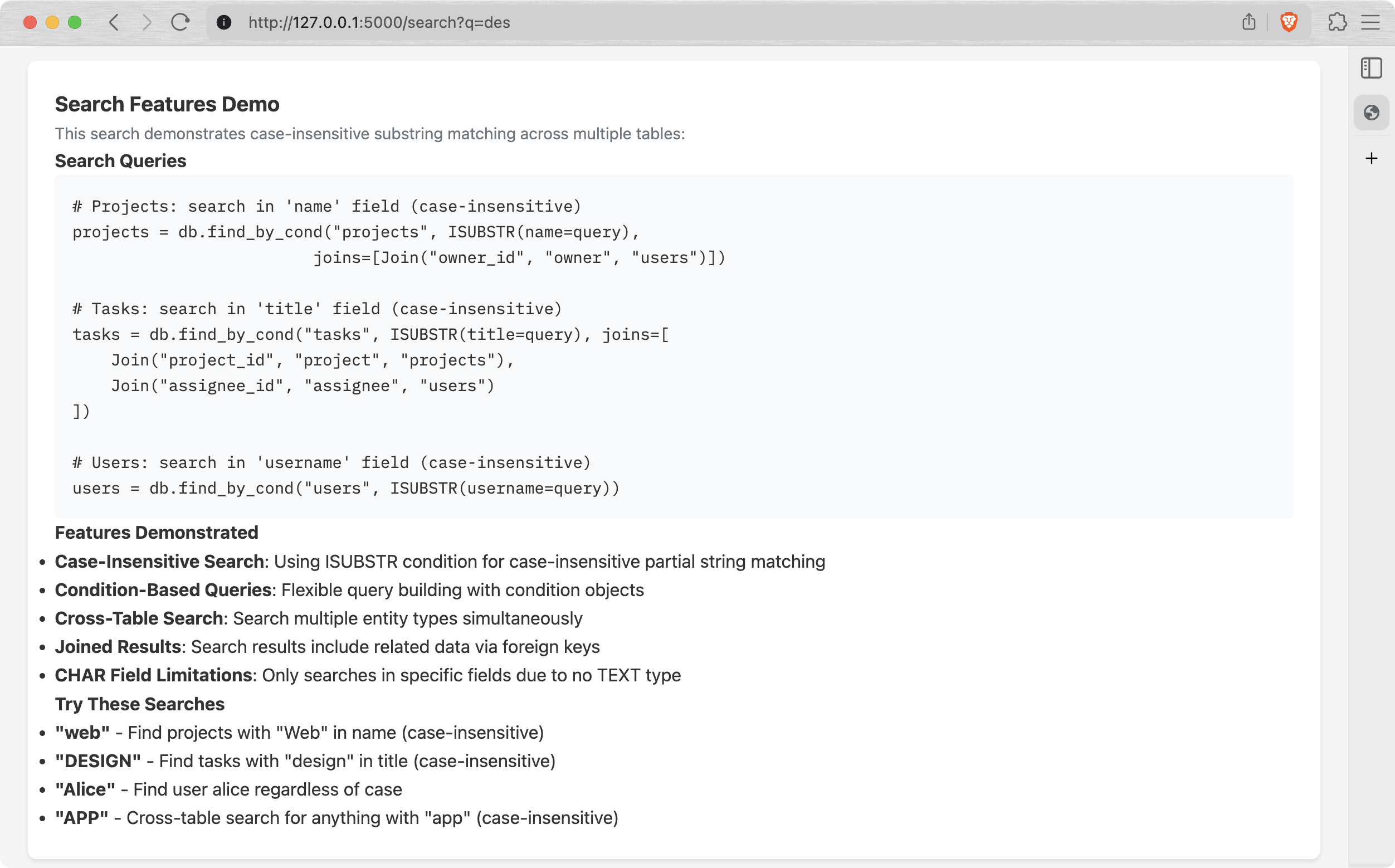
I'm still working on the TEXT field implementation, so for now all descriptions and comments are basically CHAR(200), but this will change soon.
Also, cherry on top - this demo app has been almost entirely generated by ✨Claude Code! That was a huge boost for me, because it helped focus on the essentials, delegating the boring stuff to AI.
Concurrency
Finally, this thing can be run in concurrent environment: in parallel threads or even in parallel processes. There are no parallel operations though, but at least the data won't corrupt if you run two apps using the same data directory simultaneously.
The key is a global lock. In a nutshell:
class DB:
# ...
def insert(self, table_name, values):
with self.storage.lock():
# ...
return tbl.insert(values)
def find_all(self, table_name, *, joins=None):
# ...
with self.storage.lock():
rows = self.tables[table_name].find_all()
# ...
return rows
def find_by_id(self, table_name, pk, *, joins=None):
# ...
with self.storage.lock():
row = self.tables[table_name].find_by_id(pk)
# ...
return row
def delete_by_id(self, table_name, pk):
with self.storage.lock():
self.tables[table_name].delete_by_id(pk)
def update_by_id(self, table_name, pk, values):
with self.storage.lock():
# ...
return self.tables[table_name].update_by_id(pk, values)
Actually, there are two global locks under the hood:
- A
.lockfile, essentially a global mutex shared between the processes via flock. - A
threading.RLockobject, shared between threads of a single process. However,flockis not enough, because it's basically useless within the same process.
# storage.py
class File:
# ...
@contextmanager
def lock(self):
try:
fcntl.flock(self.f.fileno(), fcntl.LOCK_EX)
yield
finally:
fcntl.flock(self.f.fileno(), fcntl.LOCK_UN)
# ...
class TableStorage:
def __init__(self, cls_tables, base_dir: str):
# ...
self._threadlock = threading.RLock()
self._lockfile = File.open(".lock", base_dir=base_dir)
# ...
@contextmanager
def lock(self):
with self._threadlock, self._lockfile.lock():
yield
It's not about atomicity, it doesn't solve data consistency in general, i.e. if you unplug your computer in the middle of a write operation, you'll most likely lose some ¯_(ツ)_/¯
Elimination of find_by and find_by_substr
Initially, I had two specific functions:
find_by(table_name, field_name, value)- an equivalent ofWHERE field_name == valuefind_by_substr(table_name, field_name, substr)-WHERE field_name LIKE substr
However, there's already find_by_cond(), allowing to search by arbitrary conditions, defined in cond.py.
So I just added EQ, SUBSTR and ISUBSTR and removed these two helpers in favor of find_by_cond(table_name, EQ(field=value)) and find_by_cond(table_name, SUBSTR(field=substr)).
One More Thing
One of the features of this database at the moment is it's size - its core implementation is less than 800 lines of Python code! I decided that it would be nice to highlight it in the Github description, and came up with a simple script, update_description.sh, which I run once in a while to count the lines of bazoola/*.py and update the repo description.
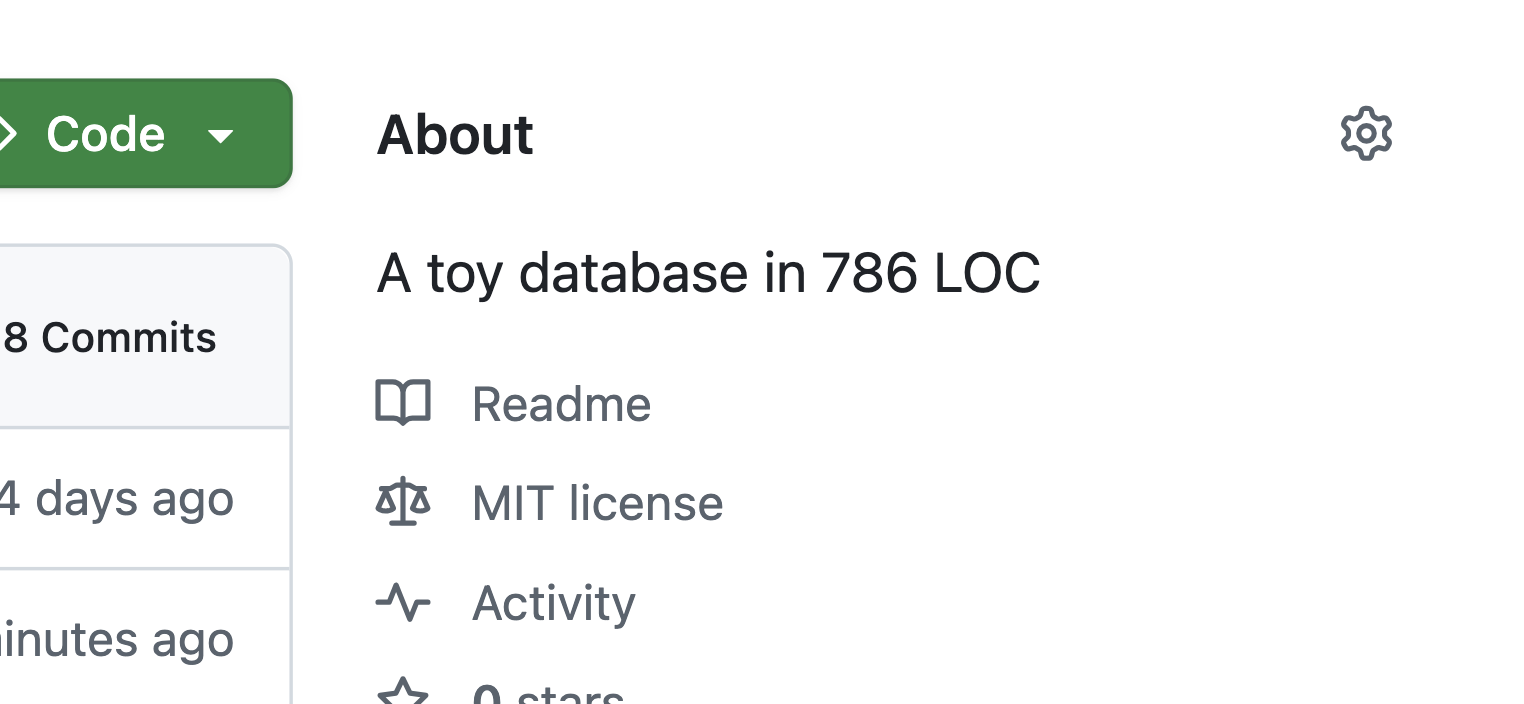
I didn't find out yet how to run it on CI, but I think this one is already good enough.
Conclusion
I treat this update as a huge leap: a month ago Bazoola was barely usable in real-life applications, and now you can build something on top of it. There's no VARCHAR or TEXT fields, the amount of conditions (EQ, LT, GT, ...) is quite limited, selecting particular fields and ordering is also not implemented, and that's why it's just a 0.0.7 release :)
I like the fact that the data files contain mostly plain text, it's easy to test and debug the logic and data consistency. Of course, I'm planning to go binary and to switch from Python to C, and those benefits disappear, but by that time I'll have a solid amount of tests and a bunch of tools for managing the data.
Stay tuned!